 Text-to-Speech Models
Text-to-Speech Models
Tacotron
Introduced by Wang et al. in Tacotron: Towards End-to-End Speech SynthesisTacotron is an end-to-end generative text-to-speech model that takes a character sequence as input and outputs the corresponding spectrogram. The backbone of Tacotron is a seq2seq model with attention. The Figure depicts the model, which includes an encoder, an attention-based decoder, and a post-processing net. At a high-level, the model takes characters as input and produces spectrogram frames, which are then converted to waveforms.
Source: Tacotron: Towards End-to-End Speech Synthesis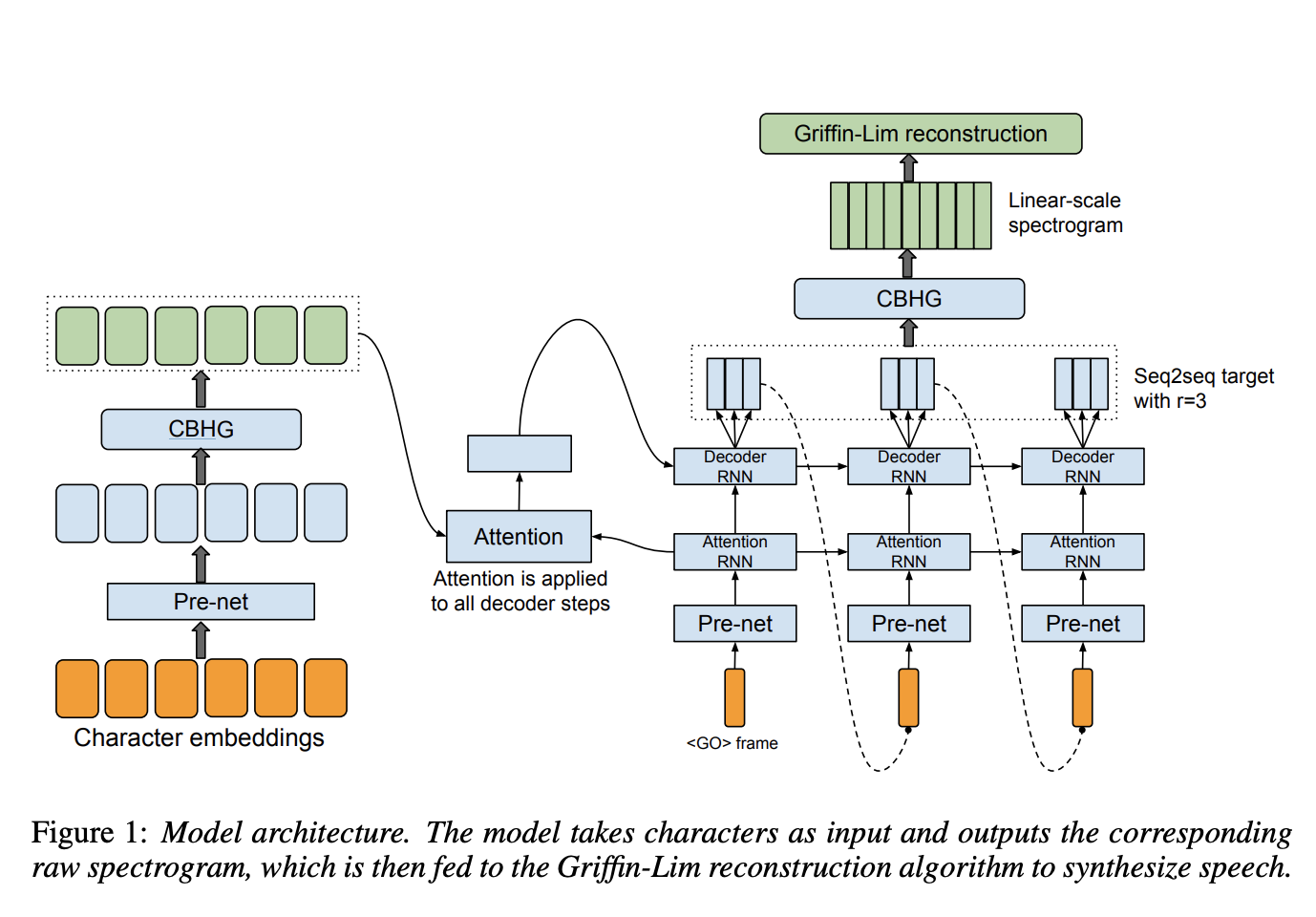
Papers
| Paper | Code | Results | Date | Stars |
|---|
Tasks
| Task | Papers | Share |
|---|---|---|
| Speech Synthesis | 42 | 38.89% |
| Text-To-Speech Synthesis | 15 | 13.89% |
| Decoder | 9 | 8.33% |
| Sentence | 6 | 5.56% |
| Voice Cloning | 5 | 4.63% |
| Voice Conversion | 4 | 3.70% |
| Speech Recognition | 4 | 3.70% |
| Expressive Speech Synthesis | 3 | 2.78% |
| Self-Supervised Learning | 2 | 1.85% |
 Additive Attention
Additive Attention
 CBHG
CBHG
 Dense Connections
Dense Connections
 Dropout
Dropout
 Griffin-Lim Algorithm
Griffin-Lim Algorithm
 GRU
GRU
 ReLU
ReLU
 Residual GRU
Residual GRU
